블록단위 I/O
모든 DBMS에서 I/O는 블록(혹은 페이지) 단위로 이뤄진다.
(즉, 하나의 레코드를 읽더라도 레코드가 속한 블록 전체를 읽는다.)
SQL 성능을 좌우하는 중요한 성증지표는 액세스할 블록개수이고 옵티마이저의 판단에 가장 큰 영향을 미치는 것도 블록 개수다.
블록단위 I/O는 버퍼캐시와 데이터 파일 I/O 모두에 적용된다.
- 데이터 파일에서 DB 버퍼 캐시로 블록을 적재할 때
- 데이터 파일에서 블록을 직접 읽고 쓸 때
- 버퍼 캐시에서 블록을 읽고 쓸 때
- 버퍼 캐시에서 변경된 블록을 다시 데이터 파일에 쓸 때
메모리 I/O vs. 디스크 I/O
1. I/O 효율화 튜닝의 중요성
- 디스크를 경유한 데이터 입출력은 디스크의 액세스암이 움직이면서 헤드를 통해 데이터를 읽고 써서 느림
- 메모리 통한 입출력은 전기적 신호이므로 굉장히 빠름
- 모든 DBMS는 버퍼캐시에서 블록을 찾아보고 없으면 디스크에서 읽어 버퍼캐시에 적재한 후 읽기/쓰기 함
- 물리적인 디스크 I/O가 필요하면 서버프로세스는 시스템에 I/O Call후 대기상태에 빠짐
- 디스크 I/O경합이 심하면 대기시간이 길어짐
- 메모리는 물리적으로 한정된 자원이므로 디스크 I/O 최소화하고 버퍼캐시 효율을 높이는 것이 튜닝의 목표
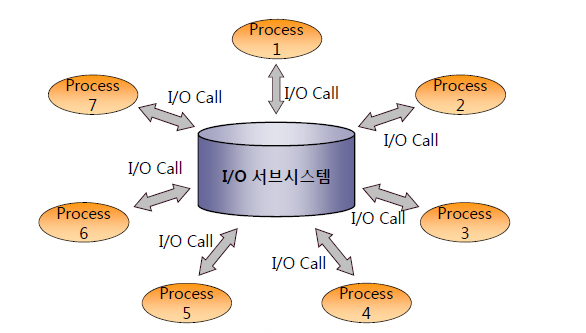
2. 버퍼 캐시 히트율
- 버퍼 캐시 효율을 측정하는 지표, 전체 읽은 블록 중 메모리 버퍼캐시에서 찾은 비율
- BCHR 비율이 낮은 것이 SQL 성능을 떨어뜨리는 주원인
BCHR = (버퍼 캐시에서 곧바로 찾은 블록 수 / 총 읽은 블록수) * 100
call count cpu elapsed disk query current rows
------ ---- ----- ------ ---- ----- ------ ----
Parse 15 0.00 0.08 0 0 0 0
Execute 44 0.03 0.03 0 0 0 0
Fetch 44 0.01 0.13 18 822 0 44
------ ---- ----- ------ ---- ----- ------ ----
total 103 0.04 0.25 18 822 0 44- Disk가 디스크를 경유한 블록 수
- query + current 가 버퍼 캐시에서 읽은 블록 수
- BCHR = (822 - 18) / 722 = 97.8%
- 총 블록 수 (Query+current)는 디스크로부터 읽은 블록수를 이미 포함함.
- 같은 블록을 반복적으로 액세스하는 SQL은 논리적인 I/O요청이 많이 발생해도 BCHR이 높게 나타남(한계)
3. 네트워크, 파일시스템 캐시가 I/O 효율에 미치는 영향
- SQL 작성시 다양한 튜닝 기법을 사용해서 네트워크 전송량을 줄이는 것이 중요
- RAC같은 클러스터링 데이터 베이스 -> 인스턴스간 캐시된 블록 공유하므로 네트워크 속도가 영향을 미침
- 근본적인 해결책은 논리적인 블록 요청 횟수를 최소화하는 것
Sequential I/O vs. Random I/O

- 시퀀셜 액세스는 레코드간 논리적 또는 물리적인 순서를 따라 차례대로 읽어 나가는 방식
- 인덱스 리프에 위치한 모든 레코드는 포인터를 따라 논리적으로 연결돼있고 이를 따라 스캔하는 것
- 테이블 레코드간에는 포인터로 연결되지 않지만 테이블 스캔시 물리적으로 저장된 순서대로 읽어나가므로 이것 역시 시퀀셜 액세스 방식
- 랜덤 액세스는 레코드간 순서를 따르지 않고 한 블록씩 접근하는 방식(위 그림에서 4,6)
- I/O튜닝의 핵심원리
- 시퀀셜 액세스 비중을 높인다
- 랜덤 액세스 발생량을 줄인다
1. 시퀀셜 액세스에 의한 선택 비중 높이기
읽은 총 건수 중 결과 집합으로 선택되는 비중을 높여야 한다.
-- 테스트용 테이블 생성
SQL> create table t
2 as
3 select * from all_objects
4 order by dbms_random.value;
-- 테스트용 테이블 데이터 건수 : 49,906
SQL> select count(*) from t;
COUNT(*)
--------
49906전체 49,906건의 레코드가 저장되어 있다.
select count(*) from t
where owner like 'SYS%'
and object_name = 'ALL_OBJECTS'
Rows Row Source Operation
---- ------------------------------
1 SORT AGGREGATE (cr=691 pr=0 pw=0 time=7191 us)
1 TABLE ACCESS FULL T (cr=691 pr=0 pw=0 time=7150 us)위 SQL은 49906개 레코드 스캔하고 1개 레코드를 선택했다.
선택 비중은 0.002%로 Table Full Scan 비효율이 높다.
읽은 블록 수는 691개다.
테이블을 스캔하면서 대부분 레코드가 필터링 되고 일부만 선택 될 경우 인덱스를 이용하는게 좋다.
create index t_idx on t(owner, object_name);
select /*+ index(t t_idx) */ count(*) from t
where owner like 'SYS%'
and object_name = 'ALL_OBJECTS'
Rows Row Source Operation
---- ------------------------------
1 SORT AGGREGATE (cr=76 pr=0 pw=0 time=7009 us)
1 INDEX RANGE SCAN T_IDX (cr=76 pr=0 pw=0 time=6972 us)(Object ID 55337)인덱스만 스캔하고 결과를 구할 수 있지만 1개의 레코드를 읽기 위해 76개의 블록을 읽어야 했다.
조건절에 사용된 컬럼과 연산자 형태, 인덱스 구성에 의해 효율성이 결정되므로 인덱스 구성 컬럼의 순서를 변경한 후 테스트 해보자.
drop index t_idx;
create index t_idx on t(object_name, owner);
select /*+ index(t t_idx) */ count(*) from t
where owner like 'SYS%' and object_name = 'ALL_OBJECTS'
Rows Row Source Operation
---- ------------------------------
1 SORT AGGREGATE (cr=2 pr=0 pw=0 time=44 us)
1 INDEX RANGE SCAN T_IDX (cr=2 pr=0 pw=0 time=23 us)(Object ID 55338)루트와 리프 단 2개의 블록만 읽고 결과를 얻었다.
2. 랜덤 액세스 발생량 줄이기
drop index t_idx;
create index t_idx on t(owner);
select object_id from t where owner = 'SYS'
and object_name = 'ALL_OBJECTS'
Rows Row Source Operation
----- ------------------------------
1 TABLE ACCESS BY INDEX ROWID T (cr=739 pr=0 pw=0 time=38822 us)
22934 INDEX RANGE SCAN T_IDX (cr=51 pr=0 pw=0 time=115672 us)(Object ID 55339)인덱스로부터 조건을 만족하는 22,934건을 읽어 그 횟수만큼 테이블을 랜덤 액세스했다.
최종 결과는 한 건이지만 많은 횟수로 랜덤 액세스가 발생했다.
drop index t_idx;
create index t_idx on t(owner, object_name);
select object_id from t where owner = 'SYS'
and object_name = 'ALL_OBJECTS'
Rows Row Source Operation
---- ------------------------------
1 TABLE ACCESS BY INDEX ROWID T (cr=4 pr=0 pw=0 time=67 us)
1 INDEX RANGE SCAN T_IDX (cr=3 pr=0 pw=0 time=51 us)(Object ID 55340)인덱스로부터 1건 출력했으므로 테이블을 한 번 방문한다.
테이블 랜덤 액세스도 1번이다.
Single Block I/O vs. MultiBlock I/O
- Single Block I/O는 한 번의 I/O Call에 하나의 데이터 블록만 읽어 메모리에 적재하는 방식
- 인덱스를 통해 액세스할 때 인덱스와 테이블 블록 모두 Single Block I/O 방식을 사용
- MultiBlock I/O는 I/O Call이 필요한 시점에 인접한 블록들을 같이 읽어 메모리에 적재하는 방식
- Table Full Scan 처럼 순서에 따라 읽을 때 인접 블록을 같이 읽는 것이 유리
- 인접한 블록 : 익스텐트내에 속한 블록
- MultiBlock I/O는 익스텐트 범위를 넘어서 읽지 않음
- 대량 데이터 읽을 때 MultiBlock I/O가 유리 (I/O Call 발생 횟수를 줄여줌)
SingleBlock I/O로 실행했을 때
create table t
as
select * from all_objects;
alter table t add
constraint t_pk primary key(object_id);
select /*+ index(t) */ count(*)
from t where object_id > 0
call count cpu elapsed disk query current rows
----- ---- ---- ------ ---- ---- ----- ----
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.26 0.25 64 65 0 1
----- ---- ---- ------ ---- ---- ----- ----
total 4 0.26 0.25 64 65 0 1
Rows Row Source Operation
---- -------------------------------
1 SORT AGGREGATE (cr=65 r=64 w=0 time=256400 us)
31192 INDEX RANGE SCAN T_PK (cr=65 r=64 w=0 time=134613 us)
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
-------------------- Waited ------- --------- -------------
SQL*Net message to client 2 0.00 0.00
db file sequential read 64 0.00 0.00
SQL*Net message from client 2 0.05 0.0564개의 인덱스 블록을 디스크에서 읽으면서 64번의 I/O Call이 발생했다.
MultiBlock I/O방식으로 수행했을 때
-- 디스크 I/O가 발생하도록 버퍼 캐시 Flushing
alter system flush buffer_cache;
-- Multiblock I/O 방식으로 인덱스 스캔
select /*+ index_ffs(t) */ count(*)
from t where object_id > 0
call count cpu elapsed disk query current rows
----- ---- ---- ------ ---- ----- ------ ----
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.26 0.26 64 69 0 1
----- ---- ---- ------ ---- ----- ------ ----
total 4 0.26 0.26 64 69 0 1
Rows Row Source Operation
----- ------------------------------
1 SORT AGGREGATE (cr=69 r=64 w=0 time=267453 us)
31192 INDEX FAST FULL SCAN T_PK (cr=69 r=64 w=0 time=143781 us
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
-------------------- Waited ------- --------- -----------
SQL*Net message to client 2 0.00 0.00
db file scattered read 9 0.00 0.00
SQL*Net message from client 2 0.35 0.3664개 블록을 디스크에서 읽었는데 I/O Call 이 9번이다.
오라클 10g부터는 Index Range Scan또는 Index Full Scan일 때도 MultiBlock I/O로 읽는 경우가 있다.
I/O 효율화 원리
- 필요한 최소 블록만 읽도록 SQL작성
- 최적의 옵티마이징 팩터 제공
- 필요하다면 옵티마이저 힌트를 사용해 최적의 액세스 경로로 유도
1. 필요한 최소 블록만 읽도록 SQL작성
SELECT a.카드번호, a.거래금액 전일_거래금액, b.거래금액 주간_거래금액,
c.거래금액 전월_거래금액, d.거래금액 연중_거래금액
FROM (-- 전일거래실적
select 카드번호, 거래금액
from 일별카드거래내역
where 거래일자 = to_char(sysdate-1,'yyyymmdd')
) a ,
( -- 전주거래실적
select 카드번호, sum(거래금액) 거래금액
from 일별카드거래내역
where 거래일자 between to_char(sysdate-7,'yyyymmdd')
and to_char(sysdate-1,'yyyymmdd') group by 카드번호
) b ,
( -- 전월거래실적
select 카드번호, sum(거래금액) 거래금액
from 일별카드거래내역
where 거래일자 between to_char(add_months(sysdate,-1),'yyyymm') ||
'01' and to_char(last_day(add_months(sysdate,-1)),'yyyymmdd') group by 카드번호
) c ,
( -- 연중거래실적
select 카드번호, sum(거래금액) 거래금액
from 일별카드거래내역
where 거래일자 between to_char(add_months(sysdate,-12),'yyyymmdd')
and to_char(sysdate-1,'yyyymmdd') group by 카드번호
) d
where b.카드번호 (+) = a.카드번호 and
c.카드번호 (+) = a.카드번호 and d.카드번호 (+) = a.카드번호어제 거래가 있었던 카드에 대한 전일, 주간, 전월, 연중 거래실적집계다.
논리적인 전체 집합은 과거 1년치인데 전일, 주간, 전월 데이터를 각각 액세스한 후 조인한 것을 볼 수 있다.
전일 데이터는 총 4번을 액세스한 셈이다.
SELECT 카드번호, SUM(CASE WHEN 거래일자 = to_char(SYSDATE-1,'yyyymmdd')
THEN 거래금액 END) 전일_거래금액,
SUM(CASE WHEN 거래일자 BETWEEN to_char(SYSDATE-7,'yyyymmdd')
AND to_char(SYSDATE-1,'yyyymmdd') THEN 거래금액 END) 주간_거래금액,
SUM(CASE WHEN 거래일자 BETWEEN to_char(add_months(SYSDATE,-1),'yyyymm') ||
'01' AND to_char(LAST_DAY(add_months(SYSDATE,-1)),'yyyymmdd')
THEN 거래금액 END) 전월_거래금액, SUM(거래금액)연중_거래금액
FROM 일별카드거래내역
WHERE 거래일자 BETWEEN to_char(add_months(SYSDATE,-12),'yyyymmdd')
AND to_char(SYSDATE-1,'yyyymmdd')
GROUP BY 카드번호
HAVING SUM(CASE WHEN 거래일자 = to_char(SYSDATE-1,'yyyymmdd') THEN 거래금액 END) > 0위와 같이 작성하면 과거 1년체 데이터를 한 번만 읽고 결과를 구할 수 있다.
2. 최적의 옵티마이징 팩터 제공
- 전략적인 인덱스 구성
- DBMS가 제공하는 기능 활용
- 인덱스, 파티션, 클러스터, 윈도우 함수 등
- 옵티마이저 모드 설정
- 통계 정보(옵티마이저에게 정확한 정보 제공)
3. 필요하다면 옵티마이저 힌트를 사용해 최적의 액세스 경로로 유도
Oracle예제
select /*+ leading(d) use_nl(e) index(d dept_loc_idx) */ *
from emp e, dept d
where e.deptno = d.deptno and d.loc = 'CHICAGO'
SQLServer 예제
select * from dept d with (index(dept_loc_idx)), emp e
where e.deptno = d.deptno and d.loc = 'CHICAGO'
option (force order, loop join)옵티마이저 힌트 사용시 의도한 실행계획대로 실행되는지 확인할 필요가 있다.
'책리뷰 > SQL 전문가 가이드' 카테고리의 다른 글
| SQL 전문가가이드 [과목3] 1장 2절 SQL 처리 과정 (0) | 2022.03.29 |
|---|---|
| SQL 전문가가이드 [과목3] 1장 1절 데이터베이스 아키텍처 (0) | 2022.03.29 |
| SQL 전문가가이드 [과목1] 1장 1절 데이터 모델의 이해 (0) | 2022.03.29 |


