728x90
반응형
데이터베이스 구조
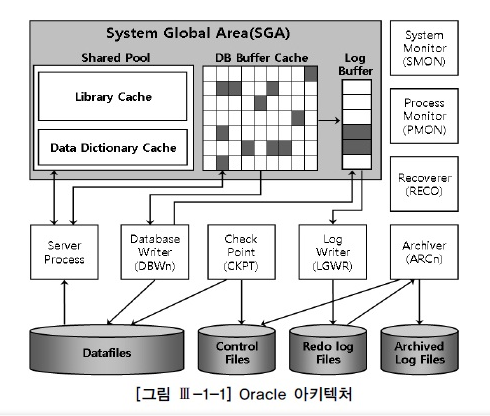
1. Oracle 구조
- 데이터베이스 : 디스크에 저장된 데이터 집합(Datafile, Redo Log File, Control File 등)
- 인스턴스 : SGA 공유 메모리 영역과 이를 액세스하는 프로세스 집합
- 하나의 인스턴스가 하나의 데이터베이스에 액세스하지만, RAC(Real Application Cluster)환경에서는 여러 인스턴스가 하나의 Database에 액세스 할 수 있다. ( 인스턴스 하나 > 여러 데이터베이스 불가)
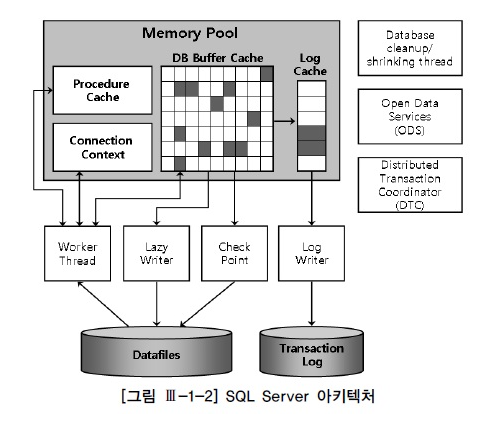
2. SQL Server 구조
- 하나의 인스턴스당 최고 3만 2767개의 데이터베이스 정의해서 사용 가능
- master, model, msdb, tempdb 등의 시스템 베이스가 만들어지며 사용자 데이터베이스를 추가해서 생성하는 구조
- 데이터베이스 하나를 만들때마다 주 데이터파일롸 트랜잭션 로그파일이 하나씩 생김
프로세스
- SQL서버는 프로세스대신 쓰레드(쓰레드기반)
1. 서버 프로세스
- 서버 프로세스는 사용자 프로세스와 통신하면서 사용자의 명령을 처리 (SQL Server > Worker쓰레드)
- SQL을 파싱하고 최적화를 수행
- 커서를 열어 SQL을 실행하며 블록을 읽어 이 데이터를 정렬해 클라이언트가 요청한 결과집합을 만들어 네트워크를 통해 전송하는 일을 처리
- 데이터파일로부터 DB버퍼캐시로 블록을 적재하거나 Dirty블록을캐시에서 밀어냄으로써 Free블록 확보,Redo 로그 버퍼를 비우는 일 등은 OS, I/O서브시스템, 백그라운드 프로세스가 처리하도록 시스템 Call로 요청
1) 전용 서버 방식
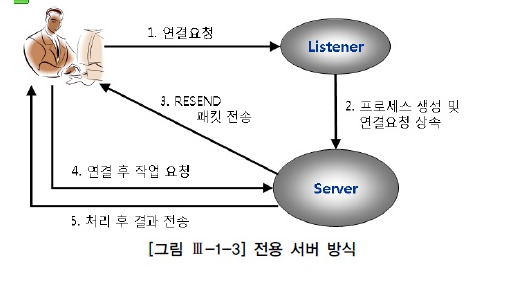
- 리스너가 서버 프로세스를 생성해주고 이 서버프로세스가 하나의 사용자 프로세스를 위해 전용 서비스를 제공한다
- SQL을 수행할 때마다 연결 요청 반복하면, 서버 프로세스 생성/해제도 반복되므로 성능이 떨어진다
- 전용서버 방식은 OLTP성 어플리케이션에선 Connection Pooling 기법이 필수
2) 공유 서버 방식

- 하나의 서버 프로세스를 여러 사용자 세션이 공유
- 사용자 프로세스는 서버 프로세스와 직접 통신하지 않고 Dispatcher프로세스를 거친다.
- Dispatcher는 SGA에 있는 요청 큐에 등록
- 요청큐에 있는 사용자 명령 처리 후 응답 큐에 등록
- Dispatcher가 응답 큐를 모니터링하다가 사용자 프로세스에게 전송
2. 백그라운드 프로세스
| ORACLESQL | SQL Server | 설명 |
| SMON(System Monitor) | Database cleanup / Shrinking Thread | 장애가 발생한 시스템을 재기동할 때 인스턴스 복구를 수행하고, 임시 세그먼트와 익스텐트를 모니터링한다 |
| PMON(Process Minitor) | Open Data Services(OPS) | 이상이 생긴 프로세스가 사용하던 리소스를 복구한다 |
| DBWn(Database Writers) | Lazywriter Thread | 버퍼 캐시에 있는 더티 버퍼를 데이터 파일에 기록 |
| LGWR (Log Writer) | Log writer Thread | 로그 버퍼 엔트리를 redo 로그 파일에 기록한다 |
| ARCn(Archiver) | N/A | 꽉찬 리두로그가 덮어 쓰여지기 전에 archive로그 디렉토리로 백업한다 |
| CKPT(Checkpoint) | Database Checkpoint Thread | checkpoint 프로시스는 이전의 checkpoint 가 일어났던 마지막 시점 이후의 데이터베이스 변경 사항을 데이터파일에 기록하도록 트리거링하고, 기록이 완료되면 현재 어디까지 기록했는지를 컨트롤 파일과 데이터 파일 헤더에 기록한다. 좀더 자세히 설명하면 wirte Ahead Logging 방식을 사용하는 DBMS는 리두로그에 기록해 둔 버퍼 블록에 대한 변경사항 중 현재 어디까지를 데이터 파일에 기록했는지 체크 포인트정보를 관리해야 한다. 이는 버퍼캐시와 데이터 파일이 동기화된 시점을 가리키며, 장애가 발생하면 마지막 체크포인트 이후 로그 데이터만 디스크에 기록함으로써 인스턴스를 복구할수 있도록 하는 용도로 사용된다.이 정보를 갱신하는 주기가 길수록 장애 발생시 인스턴스 복구 시간도길어진다. |
| RECO(Recoverer) | Distributed Transaction Coordinator(DTC) | 분산 트랜잭션 과정에 발생한 문제를 해결한다 |
데이터 저장 구조
1. 데이터 파일

1) 블록(=페이지)
- 대부분 DBMS에서 I/O는 블록 단위
- 데이터를 읽고 쓸 때의 논리적인 단위
- Oracle은 블록, SQL Server는 페이지
- Oracle : 2KB, 4KB, 8KB, 16KB, 32KB SQL Server: 8KB
- 하나의 레코드에서 하나의 컬럼만 읽으려 할 때도 레코드가 속한 블록 전체를 읽음
- 액세스 블록개수
- SQL 성능을 좌우하는 중요한 성능지표
- 옵티마이저의 판단에 가장 큰 영향을 미침
- 옵티마이저가 인덱스를 사용할지 Full Scan할지 판단하는 기준
2) 익스텐트
- 테이블 스페이스로부터 공간을 할당하는 단위
- 오라클 : 다양한 크기의 익스텐트 사용, 단일 오브젝트 사용
- SQL Server : 항상 64KB, 2개이상의 오브젝트
- 균익 익스텐트
- 64KB 이상의 공간을 필요로 하는 테이블이나 인덱스를 위해 사용
- 8개 페이지 단위로 할당된 익스텐트를 단일 오브젝트가 모두 사용
- 혼합 익스텐트
- 한 익스텐트에 할당된 8개 페이지를 여러 오브젝트가 나누어 사용
- 처음에는 혼합 익스텐트 사용, 64KB넘으면서 균일 익스텐트 사용
3) 세그먼트
- SQL Server에서는 힙구조 또는 인덱스 구조의 오브젝트
- 테이블, 인덱스, Undo처럼 저장 공간을 필요로 하는 데이터베이스 오브젝트
- 한 개 이상의 익스텐트를 사용한다는 뜻
- 파티션은 오브젝트와 세그먼트가 1:M(파티션을 만들면 내부적으로 여러개 세그먼트가 만들어짐)
4) 테이블스페이스
- 세그먼트를 담는 콘테이너
- 여러 데이터 파일로 구성된다
- SQL Server : 파일 그룹
- 데이터는 물리적으로 데이터 파일에 저장되지만 사용자가 직접 선택하지 않음
- 실제 값을 저장할 데이터 파일을 선택하고 익스텐트를 할당하는 것은 DBMS몫
- 세그먼트는 한 테이블 스페이스에 속하고, 한 테이블 스페이스에는 여러 세그먼트가 존재

2. 임시 데이터 파일
- 대량의 정렬이나 해시 작업을 수행하다가 메모리 공간이 부족해지면 중간 결과 집합을 저장하는 용도
- 임시로 저장했다가 자동으로 삭제된다
- 복구가 되지 않는다
- SQL Server는 tempdb 데이터 베이스 사용
3. 로그파일
- Oracle Redo 로그 : DB 버퍼 캐시에 가해지는 모든 변경사항을 기록하는 파일
- SQL Server 트랜잭션로그
- 메모리 버퍼 블록을 데이터 블록에 기록하는 작업은 Random I/O로 느리다
- 로그기록은 Append 방식으로 매우 빠르다 (대부분DBMS는 Append 방식 사용)
- Online Redo 로그
- 캐시에 저장된 변경 사항이 데이터파일에 기록되지 않은채 비정상 종료되면 작업내용을 잃게 됨
- Oracle 은 Online Redo로그 사용 > 캐시복구
- 최소 두 개 이상의 파일로 구성되며 파일이 꽉 차면 처음부터 재사용(라운드로빈)
- 트랜잭션 로그
- SQL Server의 로그파일
- 데이터베이스마다 트랜잭션 로그파일이 하나씩 생김(확장자 ldf)
- 가상로그파일로 불리며 로그파일의 개수가 많아지지 않도록 옵션 지정
- Archived(=offline) Redo로그
- Online Redo로그가 재사용되기 전에 백업해둔 파일
- SQL Server에는 없음
메모리 구조
시스템 공유 메모리 영역
- 여러 프로세스(쓰레드)가 동시에 액세스할 수 있는 메모리 영역
- Oracle > SGA, Sql Server > Memory Pool
- 모든 DBMS 캐시영역 : DB버퍼캐시, 공유풀, 로그 버퍼
프로세스 전용 메모리 영역
- Oracle은 PGA(Process Global Area)라고 불리는 서버프로세스 전용 메모리 영역을 가질 수 있음
- 데이터를 정렬하고 세션, 커서에 관한 상태 정보를 저장하는 용도
- SQL Server는 없음
1. DB 버퍼 캐시
- 데이터 파일로부터 읽어 들인 데이터 블록을 담는 캐시 영역
- 사용자 프로세스틑 서버 프로세스를 통해 DB버퍼 캐시의 버퍼블록에 액세스
- 버퍼캐시에서 읽고자하는 블록 찾아보고 없으면 디스크에서 읽음
- 디스크에서도 버퍼캐시에 적재 후 읽음
- 변경된 블록을 주기적으로 데이터 파일에 기록하는 작업은 DBWR 프로세스의 몫
1) 버퍼 블록의 상태
- Free 버퍼
- 아직 데이터가 읽히지 않고 비어있는 상태 혹은 데이터 파일과 서로 동기화돼 언제든 덮어써도 무방한 버퍼블록
- 데이터 파일로부터 새로운 데이터 블록을 로딩하려면 Free버퍼 확조 해야 함
- 변경이 발생하면 Dirty 버퍼로 상태가 바뀜
- Dirty 버퍼
- 버퍼에 캐시된 이후 변경이 발생했지만 디스크에 기록되지 않아 데이터 파일블록과 동기화가 필요한 버퍼블록
- 디스크에 기록되는 순간 Free버퍼로상태가 바뀌고 재사용될 수 있다
- Pinned 버퍼
- 읽기 또는 쓰기 작업이 현재 진행중인 버퍼블록
2) LRU 알고리즘
- 버퍼 캐시는 유한한 자원이기 때문에 모든 데이터를 캐싱할 수 없음
- 사용높은 데이터 위주로 버퍼캐시가 구성되도록 LRU알고리즘 사용(Least recently used)
- Free버퍼가 필요해질 때 액세스 빈도가 낮은 데이터 블록부터 밀어낸다.

2. 공유 풀
1) 딕셔너리 캐시
- 테이블, 인덱스같은 오브젝트, 테이블스페이스, 데이터파일, 세그먼트, 익스텐트, 사용자, 제약에 관한 메타 정보 저장하는 곳
- 딕셔너리 정보 캐싱하는 메모리 영역
2) 라이브러리 캐시
- 사용자가 수행한 SQL문과 실행 계획, 저장 프로시저를 저장해두는 캐시영역
- 실행계획 : 사용자가 SQL명령어를 통해 결과집합 요청시 최적으로 수행하기 위한 처리루틴 생성
- 같은 SQL에 대한 반복적인 하드파싱을 최소화하기 위한 캐시공간
3. 로그 버퍼
- 로그 엔트리가 파일에 곧바로 기록하는 것이 아니라 로그 버퍼에 먼저 기록한다.
- 일정량을 모았다가 기록하면 빠르다
- Redo로그 버퍼에 기록해두면 주기적으로 LGWR프로세스가 Redo로그 파일에 기록
- Oracle : Redo로그, Redo로그 버퍼
- SQL Server : 로그, 로그캐시
4. PGA
- 서버 프로세스는 자신만의 PGA 메모리 영역을 할당받아 프로세스에 종속적인 고유데이터를 저장하는 용도로 사용
- 다른 프로세스와 공유되지 않는 독립적인 메모리 공간
1) User Global Area(UGA)
- 전용서버 방식, 프로세스와 세션이 1:1 관계지만 공유서버 방식일 때는 1:M
- 세션이 프로새수보다 많아질 수 있는 구조
- 각 세션을 위한 독립적인 메모리 공간을 말함
2) Call Global Area(CGA)
- 하나의 데이터베이스 Call을 넘어서 다음 Call까지 계속 참조되어야하는 정보는 UGA
- Call이 진행되는 동안만 필요한 데이터는 CGA
3) Sort Area
- 데이터 정렬을 위해 사용되는 영역
- 부족할 때마다 청크 단위로 조금씩 할당됨
- 세션마다 sort_area_size파라미터로 설정가능
- 9i이상부터는 workarea_size_policy파라미터를 auto로 하면 내부적으로 알아서 할당해줌
728x90
반응형
'책리뷰 > SQL 전문가 가이드' 카테고리의 다른 글
| SQL 전문가가이드 [과목3] 1장 3절 데이터베이스 I/O 메커니즘 (0) | 2022.03.31 |
|---|---|
| SQL 전문가가이드 [과목3] 1장 2절 SQL 처리 과정 (0) | 2022.03.29 |
| SQL 전문가가이드 [과목1] 1장 1절 데이터 모델의 이해 (0) | 2022.03.29 |


